超低遅延処理のための高性能な光論理ゲートを実現【NTT】
テレコム 無料光電子融合情報処理基盤へのさらなる一歩
NTTは3月6日、超低遅延処理のための高性能な光論理素子を実現したと発表した。
電子演算回路は論理ゲートによって構成されるが、演算遅延(レイテンシ)の増大が消費電力と同様に問題となっている。
同社の研究グループは、「光の干渉」だけで動作する小型な光論理ゲート“Ψ(プサイ)ゲート”の低損失かつ高速な動作に世界で初めて成功した。この技術により、単一のΨゲートだけで代表的な論理演算(AND/XNOR/NORなど)が、超低遅延かつ波長無依存に実施できる。高速な光変調器との集積により、波長チャンネルごとに独立した演算を割り当てること(波長分割演算)が可能になる。今後、パタンマッチング処理や光ニューラルネットワークなど、特定の機能において従来にない超低遅延性を実現しうる、新たな光電子融合情報処理基盤の要素技術となることが期待される。
今回の研究成果は、英国科学誌「Communications Physics」のオンライン版で3月6日より公開。
今回の研究の一部は、科学技術振興機構(JST)CREST「集積ナノフォトニクスによる超低レイテンシ光演算技術の研究」の支援を受けて行われたという。
研究の背景
これまでCMOS(相補型金属酸化膜半導体)電子回路技術(※1)による情報処理基盤は、主に作製技術の進化と集積密度の増大によって、成長を維持してきた。しかし、電子回路の微細化によって、もれ電流や配線抵抗の増加を引き起こされることで、成長が頭打ちになりつつある。これを受け、各分野で新しい演算基盤の探索が加速している。さらに配線抵抗の増大は、電子回路の応答速度を制限するため、演算遅延(レイテンシ)はすでにどんどん悪化している。このような演算遅延の限界を克服するため、「超低遅延なナノフォトニックプロセッサ」と「ハイエンドなデジタル電気信号処理」を融合させた、「超低遅延かつ超低消費電力な光電子融合アクセラレータ」の実現が期待されている(図1)。低遅延化の原理は「光信号がプロセッサ内をほぼ光速で伝わること」に尽きるが、プロセッサ内の回路長をさらに短くする、つまり回路内の光ゲートの小型化が進むほど、さらなる低遅延化が見込める。
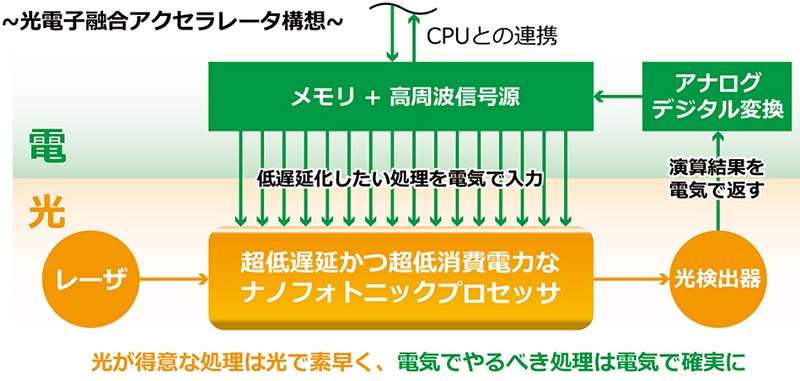
図1:超低遅延かつ超低消費電力な光電子融合情報処理基盤の概念図。
※1「CMOS電子回路技術」:電圧を印加することで論理動作を可能にする半導体素子構造のひとつ。消費電力が少なく、製造コストが安いなどの利点から、コンピュータ内のマイクロプロセッサの多くに採用されている。ムーアの法則に沿って微細化と高密度集積化が進められてきたが、半導体加工での物理的制約や消費電力の下げ止まりによって限界が見えつつある。
同研究グループでは、これまでに培ってきたナノフォトニクス技術を駆使することで、上記のナノフォトニックプロセッサの要素技術である「ナノ受光器」(※2)、「ナノ光変調器」(※3)、またこれらの高度な組み合わせである「光トランジスタ」(※4)を実現してきた。しかしながら、「光トランジスタ」のみにより光の低遅延性を損なわずに演算回路を組むことは容易ではなく、実際には様々な要素を協調させることで、初めて具体的な機能をもつ低遅延かつ低消費電力なナノフォトニックプロセッサが実現できる。とくに光の低遅延性に的を絞った光ゲートについてはこれまで未検討だった。
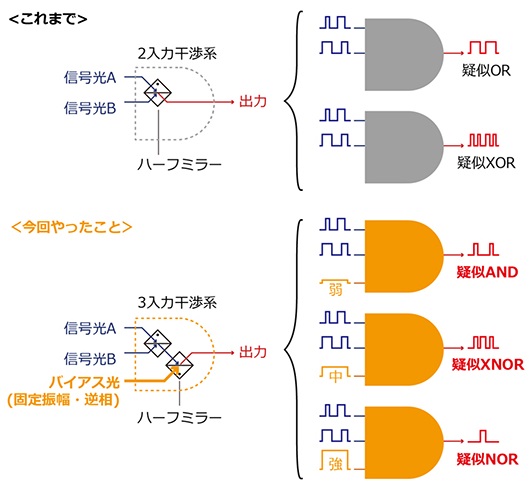
図2:2つの信号光とバイアス光の干渉による論理演算動作の概要図。
そこで同研究では、「光の干渉だけで動作する超低遅延な光論理ゲート」(※5)を世界で初めて実現したという。光の干渉は「線形」な現象なので、何も工夫をしないとできる論理演算が限られるが、新たに「バイアス光」という概念を導入することで、入力条件を整えることで代表的な論理ゲート動作が単一のゲートで実現できることが見出された(図2)。同社は「これを成熟しつつあるシリコンフォトニクス(※6)技術をベースにゲート形状を探索したところ、今回の成果を達成した」としている。
※2「ナノ受光器」:屈折率が光の波長と同程度の長さで周期的に変調された光閉じ込めの強いフォトニック結晶導波路構造内に吸収体を置くことで、劇的な小型化に成功した受光器。電気容量が小さいことから周波数特性を維持しつつ大きな負荷抵抗につなぐことが可能で、これによって電気増幅器のいらない低消費電力かつノイズの小さな受光動作が可能。
※3「ナノ光変調器」:光閉じ込めの強いフォトニック結晶で形成したナノスケールの光共振器を用いることで、きわめて小さな動作電力を実現した光変調器。
※4「光トランジスタ」:ナノ受光器とナノ光共振器を電気的に接続することで、ナノ受光器側に入力された光のエネルギーだけでナノ光共振器を駆動し、ナノ光共振器側に入力された他の光を変調できる。入力光よりも出力光の信号振幅を大きくする増幅動作、すなわちトランジスタ的な動作が可能であるため、「光トランジスタ」と呼ばれる。超低エネルギーで動作する疑似的な非線形光学ゲートとして扱うことができる画期的な光素子。
※5「光論理ゲート」:デジタル回路で用いられるブーリアン論理演算(AND、ORなど)を光信号に対して実現、あるいは模擬する素子。非線形光学ゲートを用いた方式が数多く提案されているが、非線形光学効果は微弱であり、一般に素子長と損失間にトレードオフがある。現状では、非線形ゲートだけで光のメリット(低遅延性)を損なわずに光演算回路を組むのは困難である。
※6「シリコンフォトニクス」:全反射による光閉じ込めを原理とした微細なシリコン細線導波路を主な要素とする光学素子体系。ヒータや不純物ドーピングによるpn接合の形成によって、光波の位相を制御する位相変調器を多数集積できる。近年はCMOS電子回路技術と300mm径のウエハの同じラインを用いることで均一性がさらに向上しており、大規模なマトリクススイッチなどが形成可能になっている。
研究の成果
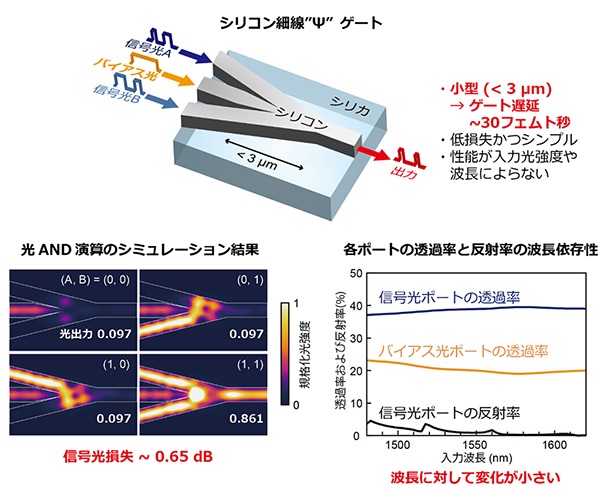
図3:小型かつ低損失なシリコン細線Ψゲートの発明。
同研究グループは、上記のシリコンフォトニクス技術を前提とした素子構造を光波シミュレーションによって探索することで、3µm長の低損失かつシンプルなシリコン細線 Ψゲート(図3上)を見出した。これを作製し、低損失・高速・波長無依存な論理演算動作を世界で初めて実験実証した。
図3上:シリコン細線Ψゲートの概念図と特長。大規模な干渉系の動作がすでに実現できているシリコンフォトニクス技術を母体として、3入力1出力の光合流素子の形状を探索したところ、ゲートの形状がギリシャ文字の“Ψ”とよく似た、およそ3µm長のシリコン細線Ψゲートが見出された。
図3左下:構造最適化したシリコン細線Ψゲートに対する光AND演算の光波シミュレーション結果。導波路交差角度などの構造を最適化することで、低損失な光AND動作が可能であることが見いだされた。
図3右下:同構造に対する各ポートの透過率・反射率の波長依存性のシミュレーション結果。光の干渉で動作するゲートの大きな特長は、信号光の絶対強度や波長に性能が依存しないことだ。さらに微細なギャップ構造を形成することで、信号光の反射率を予想以上に低減できることが見出された。構造調整によって前述した信号光およびバイアス光ポートの透過率のバランス制御が柔軟にできる。
同成果のポイントは、下記の「シリコン細線Ψゲートによる低損失かつ高速な光論理演算の実現」「単一素子における光論理演算機能の切り替え動作の実現」「入力波長に無依存な光論理演算動作の実現」。
シリコン細線Ψゲートによる低損失かつ高速な光論理演算の実現:光波シミュレーションによって最適化されたシリコン細線Ψゲートを作製してチップ化し、20Gbpsの高速な擬似ランダム光信号ビット列A、B、およびバイアス光の3つを同時入力する実験を実施した(図4上)。その結果、バイアス光なしでは出力レベルは3階調であったのに対し、適切な振幅のバイアス光を入力することで2階調の明瞭なAND動作が観測されたという(図4下)。このようなオンチップの微小な素子において光の干渉を用いた高速かつ明瞭なAND動作の観測は世界で初めてで、シリコン細線Ψゲートの低損失性がもたらしたものだ。素子長(~3µm)から光AND演算に要する演算遅延はおよそ30フェムト秒であることが推測される。電子回路でのゲート遅延は10ピコ秒程度であることが知られるため、低遅延だ。
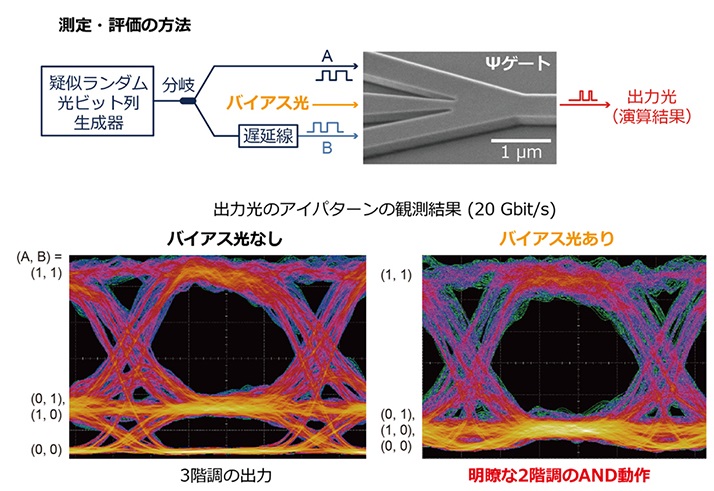
図4:シリコン細線Ψゲートによる高速光AND演算動作の実証 。
上:光論理演算動作の評価系の概要図(挿入図は作製素子の電子顕微鏡写真)
左下:20 Gbpsの光ビット信号を入力した場合の出力結果のアイパタン(バイアスなし)
右下:20Gbpsの光ビット信号を入力した場合の出力結果のアイパタン(バイアスあり)
単一素子における光論理演算機能の切り替え動作の実現:上記と同じ素子に対して、各位相関係を保ちつつバイアス光の入力強度を適切に増大したところ、XNOR動作(図5左)およびNOR動作(図5右)への動作の切り替えに成功したという。AND同様、これらの高速な光論理演算の動作の観測も世界初となる。
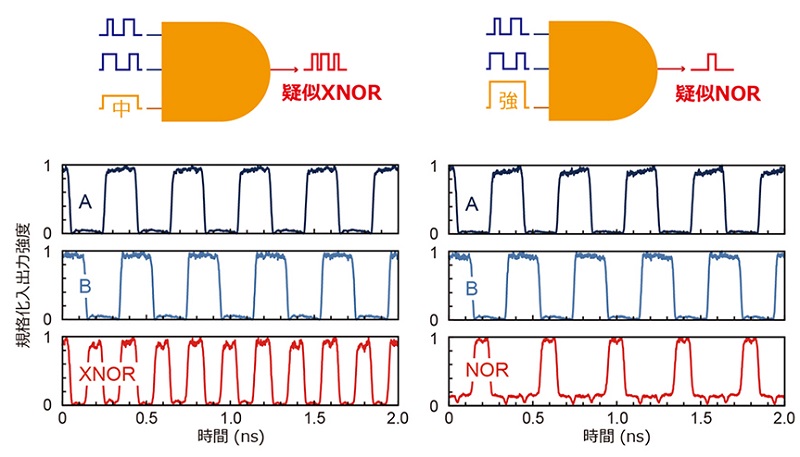
図5:バイアス光強度の調整による論理演算機能のスイッチングの実験結果(左:XNOR、右:NOR)
入力波長に無依存な光論理演算動作の実現:上記と同じ素子に対して、入力光の波長を1535から1565nmまで5nmずつ変更し、計7波長それぞれに対するAND動作の結果を重ね合わせたところ、ほぼ波長無依存な動作が可能であることを確認したという(図6)。このような明瞭な光AND動作においてここまで詳細に確認した例は同成果が初めてだ。異なる波長を同時に入力したとしても、波長間で相互作用はほとんど無いので、最終的には「波長チャンネルごとに異なるビット列と異なる論理演算を割り当てた上で、独立した演算を単一のゲートで同時に実行できる機能」(波長分割演算)が可能になることが期待される。これは非線形光学ゲートを用いた場合では実現がきわめて困難な動作の一つだ。
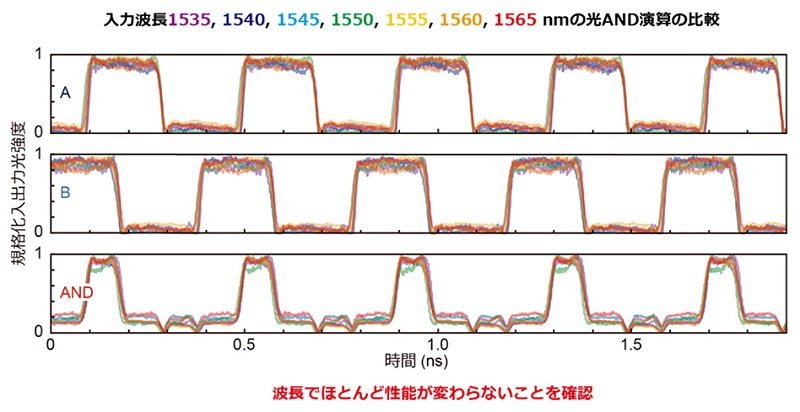
図6:異なる7波長それぞれの10Gbps 光AND演算の結果を比較した図。
今後の展開

図7:今回の成果と他の方式との比較(素子長から見積もられるゲート遅延と信号光の伝搬損失の関係)。
今回実証されたシリコン細線Ψゲートは、従来では成し得なかった小型化(低遅延化)と低損失化のトレードオフを打破する光論理素子として世界初であり(図7)、従来の電子回路技術のみでは悪化する一方であった演算遅延を、光演算技術を組み合わせることで抜本的に解決できる可能性を示すものとなる。これは今後、光電子融合情報処理基盤の要素技術の一つとなることが期待される。例えば、シリコン細線Ψゲートをツリー状に多数カスケード接続することで、CMOS技術を用いた場合よりも10倍程度低遅延な多ビットAND演算などが実現できる可能性がある。また波長選択型の高速な光変調器を組み合わせることで、波長チャンネルごとに異なる演算を同時実行する波長分割演算動作や、より大規模かつ低遅延な波長多重多ビットAND演算が可能になる見込みだ。さらに現状で入力数は3だが、5、7と多入力化することで、遅延と損失をさらに小さくできる見通しが立っているという。
近い将来、光ルータ内で読み取られる光ビット列のヘッダ情報などに対するパタンマッチング処理の一部に適用することで、より低遅延かつ安全な情報通信を支える技術となる可能性がある。また、DNAシーケンスなどのビッグデータに対するパタンマッチング処理の高速化にも適用可能であると考えられる。さらに、深層学習で話題になっているニューラルネットワークアクセラレータ(※7)の消費電力は、その90%が線形なベクトル演算で占められているといわれていることから、このベクトル演算を多入力Ψゲートで実施することで、低遅延かつ低消費電力な光ニューラルネットワークアクセラレータが実現可能になることが期待される。
※7「ニューラルネットワークアクセラレータ」:特定の応用に対する深層学習において必要なニューラルネットワークモデルを電子回路アーキテクチャによって実装し、専用演算器として高効率化と高速化をめざしたもの。これを電気デバイスではなく光デバイスを取り入れて実装しようとするものが光ニューラルネットワークアクセラレータであり、電力効率のさらなる底上げをめざすものとなる。
(補足:上記以外の重要技術)
光の干渉による論理演算動作の実現
3つの同一波長の光波の入力を想定した干渉系において、2つの信号光AおよびBに加えて、演算を補助するもう一つの光、「バイアス光」を導入することで、様々な論理演算が入力光の位相およびバイアス光の振幅と位相の制御によって実現できることを見出したという(図8)。とくにバイアス光の入力振幅だけを変えるだけで、AND/XNOR/NORと機能が切り替えられる。NANDを含めたいずれの演算動作においても、論理レベル”0”と”1”の間のコントラストは9.5dB以上が実現できる。信号光の損失は入力光強度と“1”レベルの出力光強度との比で定義する。したがって、信号光ポートの透過率が高いほど信号光の損失は小さくなる。とくに信号光の透過率が4/9を超えると、信号光の損失はゼロになる。
ただし、すべてのポートの透過率の合計が1以下であることが光の干渉を使う同ゲートの制約になる。したがって、信号光ポートの透過率の設計値を高く設定しすぎると、その分バイアス光ポートの透過率が小さくなり、動作条件を満たすために必要なバイアス光強度が大きくなりすぎてしまう。そのため、信号光とバイアス光の透過率を程よくバランスし、バイアス光を含めたすべての光入力に対する光出力強度(相対的な動作エネルギーに匹敵)も考慮に入れた上で、全てのポートの透過率を設計する必要がある。
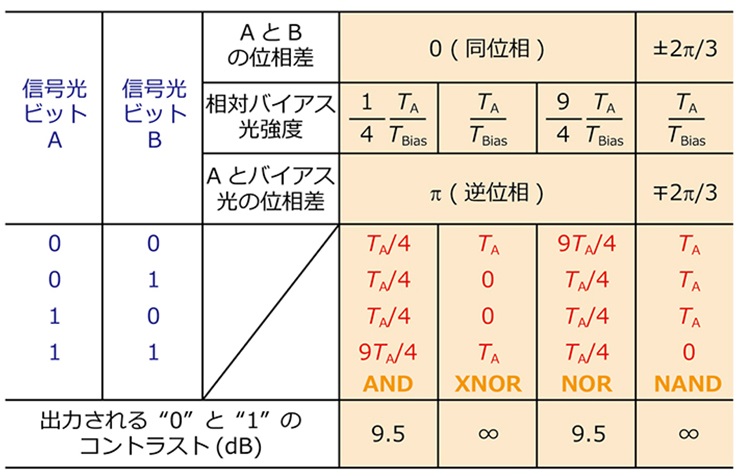
図8:3つの光の干渉によって実現できる論理演算の入出力関係(TAは信号光ポートの透過率、TBiasはバイアス光ポートの透過率)。必要なバイアス光強度は信号光の強度に比例する。